

Unlocking the WaybackMachine: 2025 Insights into Internet Archiving
Introduction to WaybackMachine
The WaybackMachine, launched publicly in 2001, is a groundbreaking service by the Internet Archive, founded in 1996 by Brewster Kahle and Bruce Gilliat. Its mission: to archive public web pages, preserving digital content for posterity. As of 2024, it stores over 866 billion web pages, spanning more than two decades of digital history.
This service combats a phenomenon known as linkrot—the gradual disappearance of web content as sites shut down, domains expire, or pages are removed. A 2024 report indicated that 38% of links from 2013 are now inaccessible, highlighting a growing challenge in maintaining digital memory. The WaybackMachine offers a public solution, enabling users to view earlier versions of websites, document changes, or retrieve information lost from the live web.
Origins and Growth of the WaybackMachine
-
Internet Archive roots: Established in 1996 as a nonprofit digital library, the Internet Archive initially received large data contributions and expanded to include books, software, music, videos, and more.
-
WaybackMachine launch: Debuted in 2001, the tool provided user-friendly access to archived web snapshots.
-
Scaling data: In 2003, growth was 12 TB/month. By 2009, it reached 3 PB with 100 TB monthly growth. Between 2013 and 2020, totals climbed from 240 billion to over 70 PB of data.
-
Breadth of content: As of early 2024, the archive held more than 866 billion web pages, alongside millions of books, videos, audio files, software, and images.
This scale reflects a decades-long commitment to preserving the web as a cultural artifact and reference library.
How the WaybackMachine Works

The system comprises three core components:
Web Crawling and Capture
It uses both third‑party crawlers and its own tools like Heritrix, a Java-based crawler developed with Nordic national libraries. It harvests publicly accessible pages, resources (CSS, scripts, images), and snapshots them over time.
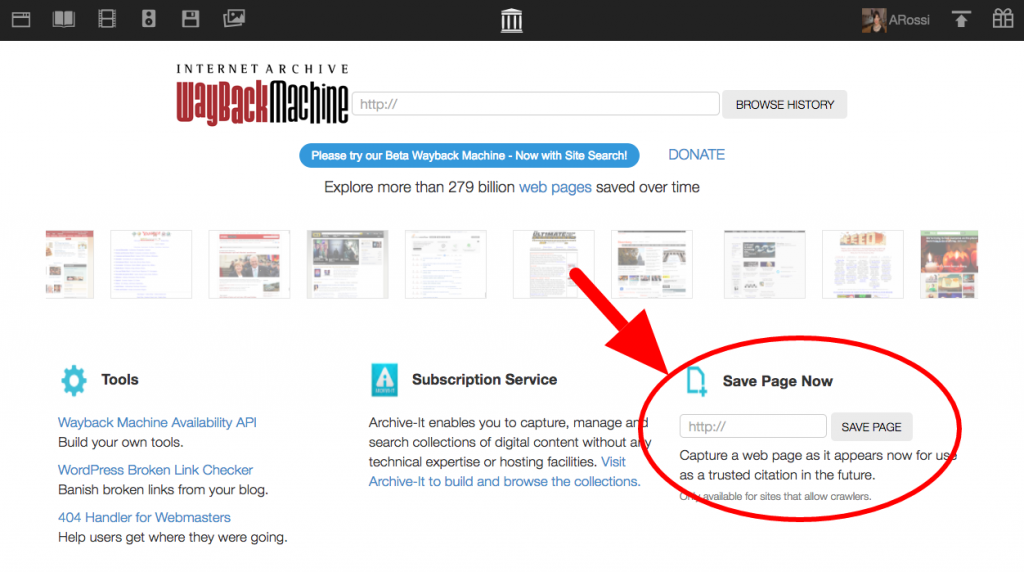
Save Page Now Feature
Introduced in October 2013, this lets users manually submit a URL to archive on demand. Later improvements added the ability to capture outlinks and generate screenshots of archived pages using Brozzler software.
Storage and Indexing
Data is stored on PetaBox racks across multiple data centers. Each snapshot gets a timestamped URL. When users browse archived pages, individual elements (e.g. style sheets, images, scripts) are served using the closest timestamp match to recreate the original page faithfully.
Snapshot frequency per site varies—some get crawled weekly, others monthly or less often depending on priorities and crawl schedules.
Key Features and User Tools
URL Playback and Calendar View
Users can enter a URL and view a calendar interface showing dots on days when the page was archived—clicking those dots launches the archived version ⎯ a simple but powerful way to time travel across the web.
Timestamps of Individual Elements
An “About this capture” panel lists the timestamps of each page element (images, CSS, scripts) so users can see exactly when each component was archived. Clicking any element shows its individual playback.
Browser Extensions and Mobile Apps
Extensions are available for Chrome, Firefox, Safari, and Edge. Mobile apps exist for iOS and Android. Extensions offer “Save Page Now” functionality and alert users when archived copies exist for missing pages.
Archive-It and Institutional Tools
Archive‑It is a subscription service allowing organizations to build and curate collections. Archived content is integrated into the broader WaybackMachine ecosystem.
Value and Applications of the WaybackMachine
The WaybackMachine serves many audiences:
Academic Research
Scholars in information science, history, social science, and digital humanities use its snapshots as primary data. Over 350 academic papers have analyzed how websites evolve over time and how archives are used.
Journalism, Legal, and Accountability
Journalists use Wayback snapshots to verify claims or expose content deletion. For example, an archived social media post contradicted a separatist leader’s later statements. Wiki editors frequently rely on archived links to cite sources reliably.
Cultural and Personal History
Individuals retrace the history of defunct domains, redesigns, or website evolution over time. Educational institutions, libraries, and volunteers preserve digital heritage through Archive‑It and community efforts.
Security and Limitations
Data Breach in 2024
In October 2024, the Internet Archive experienced a breach that exposed 31 million user records (email, usernames, hashed passwords). The site was temporarily inaccessible due to DDoS attacks. The nonprofit took measures to disable compromised scripts and strengthen security.
Limitations of the Archive
-
It cannot archive password-protected or user‑restricted content.
-
Interactive or dynamic content (JavaScript forms, Flash, embedded comments) often fails or is missing.
-
Not every page is archived; orphan pages—those unattached to any crawl path—may be overlooked.
-
Search capabilities are limited. Full-text search is not supported; “Site Search” indexes sites by metadata and links rather than page content directly.
Real-world Impact: Fighting Linkrot
The WaybackMachine addresses a serious issue: digital decay. Data shows that nearly 38% of links from 2013 no longer resolve to live content. This erosion of the web’s history undermines libraries, research, and public discourse.
Its team has emphasized the challenge of archiving content that lives behind private platforms. Archive efforts rely on selective curation and massive hardware investments to preserve cultural memory.
Technological Underpinnings
-
Heritrix, the open-source crawler, powers large-scale web harvesting.
-
Brozzler, used in Save Page Now, renders pages more faithfully including JavaScript execution.
-
The archive stores snapshots in time‑travelable timestamped URIs, indexing billions of captures with metadata, crawl provenance, and playback layering.
Future Directions and Predictions for 2030 and Beyond
-
Decentralized archiving: To ensure resilience and preservation, efforts like IPFS (InterPlanetary File System) are being explored, distributing content across networks to avoid centralized failure.
-
Expanded scope: As more content migrates to private social platforms, archiving methods must adapt to include ephemeral messaging, video logs, and rich interactive content.
-
Automated metadata and AI tagging: Enhancing discoverability with machine learning and semantic indexing can help bridge the limitations of keyword-based site search.
-
Legal and policy frameworks: Governments, libraries, and institutions may adopt policies mandating periodic web archiving—especially for official and public-interest domains.
-
User contributions: Crowdsourced archiving via browser extensions or community tools will grow, allowing citizens to preserve important digital artifacts.
By 2030, we may see more robust standards, decentralized networks, and broader access for archiving the increasingly complex and interactive web.
Conclusion
The WaybackMachine is more than just an internet archive; it is an essential safeguard against the fragility of digital memory. Holding over 866 billion pages, powered by proprietary crawlers and community submissions, the system empowers academics, journalists, historians, and ordinary users to reclaim vanished content.
Despite limitations—such as difficulty archiving dynamic content and platform-specific restrictions—it remains the most comprehensive public record of the web’s history. As digital decay accelerates, its role grows ever more critical.
Looking ahead to 2030 and beyond, developments like decentralized networks, AI-enhanced indexing, legal mandates, and community-driven archiving may further strengthen our ability to preserve culture and information online.
FAQs
1. What exactly is the WaybackMachine and who runs it?
The WaybackMachine is a digital archive of the web provided by the Internet Archive, a nonprofit founded in 1996. It preserves snapshots of public web pages over time and offers public access to them.
2. How do I save a web page manually?
Use the “Save Page Now” feature on the archive’s website, or install a browser extension to archive a page instantly, including optional screenshots or outlinks.
3. How often is content archived?
It varies. Popular or frequently updated sites may be crawled monthly or weekly; others much less often. Users can request immediate archiving via Save Page Now.
4. Can WaybackMachine archive social media posts or dynamic content?
Archiving dynamic or interactive elements (like comments, scripts, embedded apps) is limited. Some dynamic content may not be preserved accurately.
5. Is everything archived indefinitely?
While snapshots are stored across multiple data centers, archiving completeness depends on crawler access and technical limitations. Not all pages are guaranteed to be preserved.
6. Are archived pages legal to reference or link to?
Yes. WaybackMachine provides permanent URLs for archived copies that can be cited or linked. However, users must respect copyright and terms of use related to content reuse.